A Theory of Information Systems
This chapter documents a theory of information systems, upon which Ampersand generates information systems.
The purpose of an information system is to make data meaningful to its users. Users have their own tasks and responsibilities and may work from different locations and on different moments. This collective use by multiple users serves a purpose which we will loosely call "the business". To preserve meaning, the business maintains semantic constraints on the data, amidst of all changes that are going on around them.
Information systems are typically used by actors (both users and computers) who are distributed and work with data all the time. As a consequence, the data in a system changes continually. In practice, actors "talk to" the system through an ingress mechanism, which connects each user to the right interface(s). The ingress function is provided by the deployment platform, so it is beyond the scope of this paper. Also, every interface runs independent of other interfaces, meaning that each interface can be stopped, (re)started and substituted without disrupting the other interfaces.
Every system contains a dataset, which represents the state of the system. Every interface produces and consumes events that may change the state of the system. This state is represented in a persistent store, aka the database. Events that the system detects may cause the state to change.
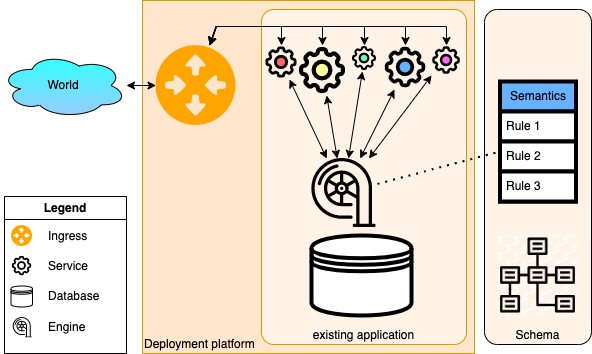
To keep our theory technology independent, datasets are assumed to contain triples. This makes the theory valid for any kind of database that triples can represent, such as SQL databases, object-oriented databases, graph databases, triple stores, and other no-SQL databases. The system's semantics is represented as constraints, which most database management systems refer to as integrity rules. The purpose of integrity rules is to keep the constraints they represent satisfied.
An information system is a combination of dataset, schema, and functionality. Each is defined in a separate section.
Datasets
A dataset describes a set of structured data, which is typically stored persistently in a database of some kind. The notation refers to the dataset of a particular information system . The purpose of a dataset is to describe the data of a system at one point in time. Before defining datasets, let us first define the constituent notions of atom, concept, relation, and triple.
Atoms serve as data elements. Atoms are values without internal
structure of interest, meant to represent atomic data elements (e.g.
dates, strings, numbers, etc.) in a database. From a business
perspective, atoms represent concrete items of the world, such as
Peter, 1, or the king of France. By convention throughout the
remainder of this paper, variables , , and represent atoms.
All atoms are taken from an infinite set called .
Concepts are names that group atoms of the same type. All concepts are
taken from an infinite set . and
are disjoint. For example, a developer might choose to classify Peter
and Melissa as Person, and 074238991 as a TelephoneNumber. In
this example, Person and TelephoneNumber are concepts. In the
sequel, variables , , , will represent concepts.
The relation is the instance relation between atoms and concepts. The expression means that atom is an instance of concept . This relation is used in the type system, in which assigns a concept to every atom in the dataset.
Relations serve to organize and store data, to allow a developer to represent facts. In this paper, variables , , and represent relations. All relations are taken from an infinite set . is disjoint from and . Every relation has a name, a source concept, and a target concept. The notation denotes that relation has name , source concept , and target concept .
Triples serve to represent data. A triple is an element of .
A dataset is a tuple that satisfies:
This equation defines what it means for a triple to be well-typed.
For example,
is a triple.
The equation says that Peter is an instance of
Person and 074238991 is an instance of TelephoneNumber. In
practice, users can say that Peter has telephone number 074238991. So,
the "thing" that Peter refers to (which is Peter) has 074238991 as a
telephone number. This "meaning from practice" has no consequences in
the formal world. Users are entirely free to attach a practical meaning
to a triple.
The notations and are used to disambiguate and when necessary. Every dataset is an element of an infinite set called . To save writing in the sequel, the notation means that .
A relation can serve as a container of pairs, as defined by the function . It defines a set of pairs, also known as the population of :
So, for every dataset :
For a developer, this means that the type of an atom depends only on the relation in which it resides; not on the actual population of the database. This allows for static typing, which has well established advantages for the software engineering process [@HanenbergKRTS14; @Petersen2014].
Schemas
To design an information system, a developer defines a schema in which she defines concepts, relations, and rules. Together, the concepts, relations, and rules capture the semantics of an information system [@Spivak2012]. Each rule in a schema serves to constrain the dataset, to ensure its semantic integrity. Every rule is an element of an infinite set called , which is disjoint from , , , and . In this paper, variables and represent rules.
A type system in Ampersand [@vdWoude2011] identifies certain rules that are provably false. It also ensures that all rules can be interpreted within the set of relations in the schema. Due to this type system, the Ampersand compiler only generates code for scripts without type errors. As a result, for every rule in the schema, there is a predicate that says whether dataset satisfies rule . A discussion of the type system is out of scope because this paper only makes use of the predicate .
Rules serve as invariants, i.e. constraints that the data in the database must satisfy at all times. At times in which the dataset does not satisfy a rule, that rule is said to be broken. In those cases, something or someone must take action to fix the situation and restore invariance of that rule.
A schema is a triple , in which is a finite set of concepts, is a finite set of relations, and is a finite set of rules. The notation refers to the schema of information system . Disambiguation sometimes requires to write , , and rather than , , and respectively.
In order to do static type checking, all concepts and relations must be "known" in the schema:
We say that a triple befits schema if it satisfies these requirements.
A special kind of rule is used for specialization. The rule (pronounce: is a ) states that any instance of is an instance of as well.
This is called specialization, but it is also known as generalization or subtyping. You need specialization to allow statements such as: "An employee is a person" or "A human is a mammal". The specialization rules in a schema form a partial order , meaning that is reflexive, transitive, and antisymmetric. Specialization rules are special for two reasons: Firstly, the system keeps satisfied automatically by changing whenever needed. This means that a system that contains rule can never be brought into a state in which is False. This allows for certain run-time optimizations, which are beyond the scope of this paper. A second property that sets specialization rules apart, is that they play a role in the Ampersand compiler. For example, code that determines equality between atoms only works for atoms that are an instance of the same concept. To ensure that this does not result in problems at run-time, users are required to write all specialization rules explicitly.
As a result, if an atom is an instance of concept and , this atom has all properties that atoms of type have.
Information Systems
This section defines the notion of information system. As before, a suffix disambiguates the elements of this definition when needed.
Definition 1 (information system).
An information system is a tuple , in which:
dataset as defined previously;
schema as defined previously;
is a set of roles;
is the maintainance relation between roles and rules.
A role is a name that identifies a group of users. It serves as a placeholder for a person or a machine (i.e. an actor) that works with the dataset (i.e. create, read, update, or delete triples). The purpose of a role is to mention an individual user (human) or an automated actor (bot) without knowing who that user is.
The system is at rest when every rule in the schema is satisfied:
However, the system continually registers events that insert or delete triples in its dataset, which may cause rules to be broken. This requires a reaction to restore invariance. Example: if a rule says that every request must be acknowledged, the receipt of a request (which is an event) will violate this rule. Sending a message that acknowledges this receipt (another event) will cause the rule to be satisfied again. During the time between the receipt of the request and sending the acknowledgment, the rule is (temporarily) not satisfied.
Ampersand assumes two ways of enforcing satisfaction of rules: automatic or manual. Manual enforcement is specified by the developer by assigning a rule to a role . Any actor with role , whether person or machine, can restore invariance of rule by inserting or deleting the right triples. For this reason, every rule is assigned to at least one role by means of the relation :
means that role must keep rule satisfied, i.e. to keep true. As long as rule is broken, the system should notify actors in the role(s) that are administered in to do something about it.
Automatic enforcement is specified by the developer with a special syntax, the enforcement rule. An enforcement rule specifies not only the rule, but also the way to restore invariance. The system features an engine that restores invariance of all enforcement rules without unneccessary delay. Whenever the dataset violates an enforcement rule, this engine will make other changes to the dataset to satisfy that rule. Hence, the rule is not satisfied during a small, finite amount of time.
The system contains a dedicated role for the enforcement engine, so every rule has at least one role in the relation , means that all roles together are keeping all rules satisfied.
Example
Having defined an information system in mathematical terms, let us discuss a small example. It is written in the language Ampersand to make it more appealing to read. Let us first define a dataset of just a handful of triples and three relations.
RELATION takes[Student*Course] =
[ ("Peter", "Management")
; ("Susan", "Business IT")
; ("John", "Business IT")
]
This declaration introduces a relation with the name takes, source
concept Student, and target concept Course. The informal meaning of
this relation is that it states which students are taking which courses.
The example system also has a second relation that states which modules are part of which course.
RELATION isPartOf[Module*Course] =
[ ("Finance", "Management")
; ("Business Rules", "Business IT")
; ("Business Analytics", "Business IT")
; ("IT-Governance", "Management")
]
The third and last relation states which students are enrolled for which module. It is left empty for now.
RELATION isEnrolledFor[Student*Module]
A rule, EnrollRule completes the semantics It states that a student
can enroll for any module that is part of a course he or she takes. In
Ampersand, which is a syntactically sugared form of relation
algebra [@JoostenRAMiCS2017], each rule has a name and each rule has a
role to maintain its invariance:
RULE EnrollRule: isEnrolledFor |- takes;isPartOf~
ROLE Administrator MAINTAINS EnrollRule
The semantics of this rule defines as:
Rule EnrollRule is satisfied because relation
is empty.
Now let us check the requirements to verify that this example defines an information system. The Ampersand compiler generates a dataset , which contains a set of triples and a relation . It defines the set of triples as:
The relation contains the pairs:
The tuple is well-typed, so this is a dataset as introduced before.
The Ampersand compiler generates a schema , which contains concepts, relations and rules. It defines the set of concepts:
It defines the set of relations:
And, it defines the set of rules to
contain just one rule: EnrollRule.
This example contains no specialization.
So, the schema
satisfies all requirements mentioned above.
Now let us check the definition of information system. Ampersand
generates a set of roles . The
relation contains one pair only,
, instructing
the run-time engine to forward all violations of EnrollRule to an
administrator so she can keep EnrollRule satisfied.
We can see that the only rule,
EnrollRule, is satisfied, which completes the requirements for
.
This concludes the argument that is an information system.
Relation to other theories
The following table compares the language used in the world of information systems with related worlds. It is compared with Ampersand, because we use Ampersand to design information systems. It is compared with the world of software, because Ampersand generates software. It is compared with the world of model theory [ref required], because the formal theory of Ampersand can be understood formally in model theory.
| information system | Ampersand | software | model theory |
|---|---|---|---|
| rules | script | program | theory |
| data | population | state | model |
| formal statement | term | condition | term |
| generator | generator | compiler | |
| store | database | database | |
| interface | interface | interface |
The following theoretical topics are relevant for Ampersand.
Relation Algebra [Maddux 2006] Ampersand uses heterogeneous relation algebras with specialization as a language to specify information systems. This is existing theory. It is relevant for people who specify information systems. It allows them to formalize business rules. Thus, they can ensure on design time that an information system complies with business rules.
Rewrite systems The Ampersand compiler manipulates relation algebra terms. For this purpose, it uses rewrite systems. This is existing theory. It is relevant for people who make the Ampersand-compiler generate efficient code.
Type systems The Ampersand compiler ensures that every type-correct specification can be built [1]. For this purpose it has a type system, which signals type-errors in Ampersand-scripts. The Ampersand-compiler generates code only for scripts without type errors.
Generating computations It is possible to generate code to keep constraints satisfied. The theory for this is under development. It is relevant for automating tasks in information systems.
Compiler theory Ampersand is a compiler. Its syntax is parsed by the Parsec-module of Haskell. A hand-written generator embodies the semantics. The theory is existing. This subject is relevant for people who wish to change the language of Ampersand.
Each of the following sections treats on of the topics mentioned above (work to be done).
[1] Michels, G., Joosten, S., van der Woude, J., Joosten, S.: Ampersand: ApplyingRelation Algebra in Practice. In: de Swart, H. (ed.) RAMICS 2011. LNCS, vol. 6663,pp. 280–293. Springer, Heidelberg (2011)